



LLMs and the Business of Fiction (part 1)
Part 1 of a discussion about Large Language models, their limitations, and ethical uses for them in context of the business of writing fiction.

I want to talk about Large Language Models (LLMs) and the business of writing fiction. I have some expertise in both these areas: I am a well published author of prose fiction and writer comics, as well as a professional data scientist who published an academic paper about LLMs last year.
I’ve been working on this post for months now. I admit that I’ve hesitated to add to the noise, because I am deeply embarrassed by the way that such a promising tool has been sold to the public. The tech business has downplayed the applications I think are credible and instead has hyped those that are exploitative, insecure, and dangerous. But with the hype cycle peaking and even the publishing establishment starting to emit credulous thinkpieces, I think it’s time for a realistic look at the technology.
A side note: most of the art in the post are scrap-paper doodles I made while I was fretting about how to put this together instead of writing.

This technology exploits the work of writers and is likely to damage our work conditions. But it does offer some genuinely useful applications, and it’s not going back into the box. Creative people need to act now if we are going to have a say in how this unfolds. The current Writer’s Guild of America strike which has shut down Hollywood is ground zero for these concerns, but the WGA only represents a subset of writers. The rest of us cannot afford to stand idly by.
There’s a lot of ground to cover in this discussion, and it’s going to take more than one post. In this first article I’m going to cover the basics: what LLMs are, how they work, and what ethical problems they present. I’ll then loo at what they are good for and what they are bad at. In a following post I will talk the effects they will have on the writing business. For those of you paying attention we can already see these starting to take shape and they are, indeed, ugly.
One last note. In this series of posts, I am talking specifically about LLMs, and writing. I believe that generative AI has a different threat profile when it comes to art and to music and other creative media. I have diminishing levels of expertise when it comes to those topics, but I will address them in future posts—likely with the help of some friends.
Let’s get to down it.
Who is Your Language Model and What Does He Do?
LLMs, like ChatGPT (OpenAI/Microsoft) and Bard (Google,) are a form of generative AI that are is skilled at manipulating text. Given a prompt of a few (or a lot) of words, a language model will formulate a response (sometimes called a completion) to your request based on its understanding of language. Responses are astonishingly coherent, grammatically correct, and convincing—even when they are factually wrong. In order to understand why, we need to understand how they work.
Before we start, my earlier post https://jasonfranks.substack.com/p/supernova-generative-ai-and-creative is a technical primer and I encourage you to give it a read, if you haven’t already. If you can’t be bothered, here is the Franks Notes version:
Large Language Models are neural networks that are trained on enormous quantities of text—hundreds of billions of records—scraped from the internet to model language. A language model is a map that calculates which words (or parts of words) will precede or succeed any other word in a stream of natural language. This gives it an understanding of how words work in context of language.
These models are sub-logical. They do not have rules or facts. They do not know grammar. They just know probabilities about how to chain tokens together in a way that resembles language.
LLMS are trained by example to give you the answers they think you want to hear.
Capabilities and Limitations of LLMs
Language models present a very powerful set of tools for manipulating language. That’s it. The hype has been deceptive and the vendors of AI software have, if I am charitable, done very little to correct the public’s misconceptions about what these tools can do. If I am feeling less charitable I might say that they have actively promoted these misconceptions. If I’m brutally honest, I think that some of them have bought into their own hype.
The technical people I have dealt with at different places are smart and honest about the capabilities of their LLMs, but very little of this has filtered through to the consumer-facing push that most lay-people see and I find this very troubling. This is why many people are shocked and upset that LLMs lie or hallucinate, although this is absolutely to be expected if you understand how the technology works.
These AIs are trained to generate text that sounds cogent and convincing. They try to predict the sequence of words that they think you want to hear as an answer based on raw probabilities. LLMs know how language works—any other knowledge they possess is a side effect, at best.
You cannot expect them to be accurate or truthful because they do not know what the truth is.
LLMs are not designed for information retrieval and will never, in their current architecture, be a reliable source of knowledge. Even if they are trained on documents that are truthful and free of bias, there is no guarantee that an LLM will reassemble words from them in a truthful way.
LLMs have no initiative nor capacity to experience anything other than language and cannot come up with new ideas. They can remix and mash up language, but they are not creative and can not be credibly used to generate fiction from whole cloth. This is plagiarism. The results are terrible and easily spotted.

LLMs cannot reason out an argument, they cannot solve logic problems, and they cannot even do simple arithmetic. They understand how humans might express these ideas in text and can give the semblance of performing these tasks, but it’s an illusion. Let me give you an example:
An LLM knows that when a human writes “1+1” it’s usually going to be followed by =2”, but they cannot calculate—only memorize. Have a look at ChatGPT giving two different, incorrect answers to the same simple arithmetic question.


The correct answer is 1. ChatGPT is close, but the calculator wristwatch I had when I was 12 is better. My 8-bit watch (I doubt it was even 8 bits—somebody correct me?) could do arithmetic. ChatGPT, for all its size and power, can only take an educated guess. Let us not forget that adding numbers is the killer app for which computers were first invented.
This is why image generation AIs are so prone to painting pictures of people with too many fingers or teeth. They don’t know the correct quantity of human appendages, and even if they did, they are unable to count.
Ethical Problems with LLMs
Leaving aside the way that bad actors are (already) using LLMs to generate disinformation and scale up cyber-crime, there are some serious ethical problems with the tools. The first is the source of the data used to train the models.
Vendors are notoriously cagey about what data used to train their LLMs and it appears that a large amount of it is copyrighted material. Authors Mona Awad and Paul Tremblay have initiated a class action lawsuit against OpenAI claiming exactly this. For their part, OpenAI is talking about leaving the European Union if legislation requiring them to disclose the use of copyright materials is passed. I will let you draw your on conclusions.
Copyrighted material is not the problem to be found in training data. Your personal data may also be used to train an LLM, and this has enormous security ramifications. Just about every free internet platform or app requires us to agree to Terms of Service that allow them to legally use for our data for advertising and research—which includes training AI models. It’s been shown as early as 2020 that LLMs can leak personal data—and even if they couldn’t, OpenAI had a data breach as recently as March of this year. Also, be aware that any data you provide in a prompt is also likely to end up in the training set for the next model. So for the love of Satan, don’t give them your PIN.

Data privacy legislation like the GDPR does give consumers in Europe legal rights over what happens to their data (e.g., the right to be forgotten), but this can be difficult to enforce when the data is held by an entity that resides outside of their jurisdiction. Even inside the jurisdiction it can be difficult, as German photographer Robert Kneschke discovered when he asked to have his work removed from the LAION dataset and found himself threatened with a lawsuit.
Bias from the training data is the other major ethical concern, because its effects are insidious, and because it is very difficult to eliminate. Biases are not necessarily prejudices or preconceptions expressed directly in the records used to train an AI—they may also arise just from the relative quantities of the records. If you are training an AI to predict successful applicants for a job, and most of the applicants in the training data are men, the model is going to be biased in favour of male candidates. AI training favours the majority, so if there are few records to give certain facts, or a particular side of a story, that signal is more likely to be lost.
We need protections to ensure that LLMs are ‘ethically sourced’ before we consider any benefits they offer to writers, rather than a vector for exploiting us.
Can LLMs Be Useful for Writers Without Being Plagiarism Machines?
Language models can be useful for many tasks that are not plagiaristc. I think the idea that an LLM can write a worthwhile story, or screenplay, or a novel for anybody without painstaking oversight by a human writer is a fantasy (which I will explore in another post). Their true value is not in their ability to generate new text, but to manipulate existing language.
To begin with, LLMs are good at summarizing. Writing synopses is a task that many writers struggle with. We are trained to write stories or books or scripts and spend most of our time doing that. Condensing a large work into a 3, or 2, or 1 page synopsis, much less a 1 paragraph summary, is a distinct skill, and it’s not something most of us practice every day.
LLMs can be used to help transform a too-long summary into one that fits an arbitrary length. Think of it as as lowering of the resolution of your work. LLMs offer a way of quickly prototyping these documents, allowing writers to focus more on the voice. (Also bear in mind, if you have a strict wordcount, you can’t trust an LLM to hit it, since they… cannot count…)

Other good applications are more analogous to find-and-replace—an essential, but limited, feature of modern word processing software. Even if you are technical enough to write regular expressions, find-and-replace a cannot easily cope with the complexities of English grammar. LLMs, on the other hand, are very good at this.
Suppose you want to change the tense of a passage:

Or change the point of view:
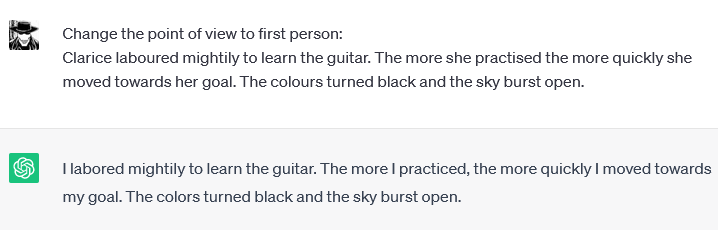
Or switch from Australian English to American:

Or change a character’s pronouns:
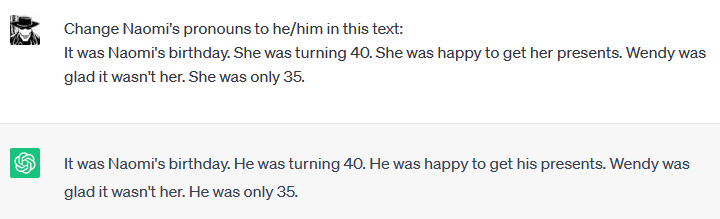
This is mission impossible with find-and-replace, but an LLM can ably assist with these tasks. Sometimes it gets it wrong (it has failed to distinguish which sentence applies to Wendy in the latter example), but no serious professional is going to submit work that’s been adjusted by an LLM without double-checking it—just as they wouldn’t after using find-and-replace, right? Right?
I myself am unlikely to use LLMs to assist in my work, because I’m old and set in my ways, but I am under no illusions about the adoption of this technology by younger writers. I’m okay with that, provided the LLMs they use are created ‘ethically sourced’—by which I mean, trained with data that is in the public domain, or used with the consent of the authors. Perhaps the authors could even be compensated for the use of their work. Let me invoke Harlan Ellison:
All of which leads me to what will be part 2 of this topic: the WGA strike and how LLMs will shape (and have already begun to shape) the business of writing. Coming soon.
In Summary
LLMs are not credible tools for information retrieval, reasoning, or calculation tasks, or for writing fiction, but they are useful for manipulating text. As they become widespread we must address issues with them being trained on stolen IP and personal data. We also need to be aware of biases propagated through AI systems, which may be more subtle or different from those we see from purely human output.
News Roundup
This weekend I will be a guest at Metro Comic Con, so if you’re in Melbourne and you’re at the show, please come by. I’ll have copies of all of my books and I think a very small number the limited preview run of FRANKENSTEIN MONSTRANCE #1, if you’re looking for something to read.

The North American version of Bloody Waters is out on July 11th, so I’m going to write about that next week. If you are super-keen it is currently available for pre-order, direct from Outland Entertainment or on Amazon. The book is already available everywhere else, if you’re keen and live in a different region.
Also, This Fresh Hell, which my short story Contract Lore, about big data, surveillance capitalism, and the devil, is now available in North America and Australia.
And finally, if you work in records and information management, I will be presenting about the opportunities and threats to the business afforded by LLMs will at RIMPA in Geelong on July 21st, so once again, if you’re a local please say hello!
I know that was a long one. Thanks for persevering!
Franksly yours,
— Jason
That was a bloody good write up, mate. Thanks for putting all of this together. I’m working around this for schools and am drawing in a lot of reading to inform the head, and I appreciate your intelligence and explanations of so much.